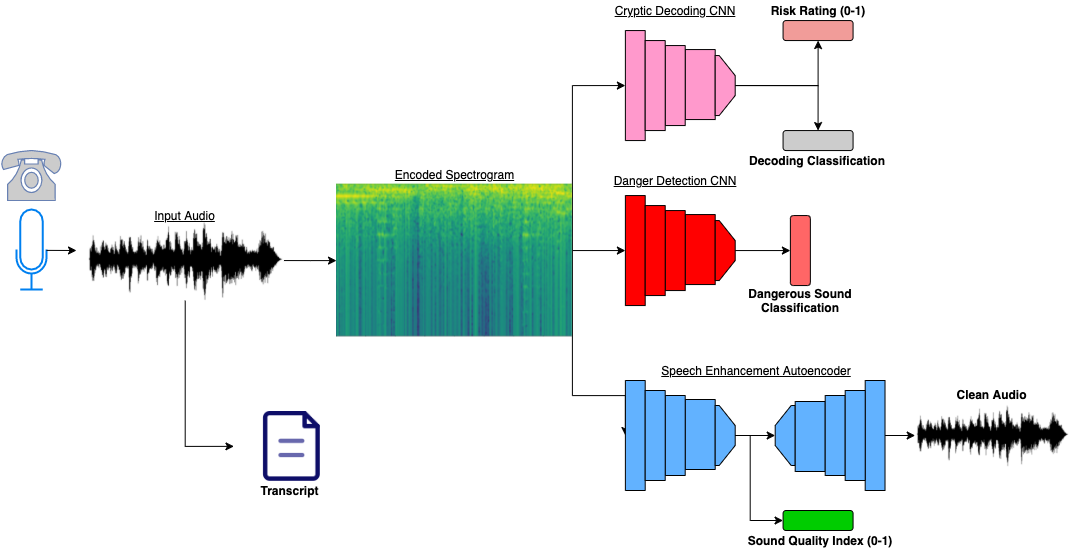
AI-Based Audio Classification and Enhancement
We leverage state-of-the-art research to train and implement effective and accurate deep learning solutions for 911 operators. The warmstarted audio files are quered to the web server. A single audio file is simultaenously fed to each of the 3 networks in an ensamble scheme, and a variety of outputs are fed to the frontend. Below are details on the specific model architectures we implement from recent research. The figure below is a diagram of our triple neural network architecture.
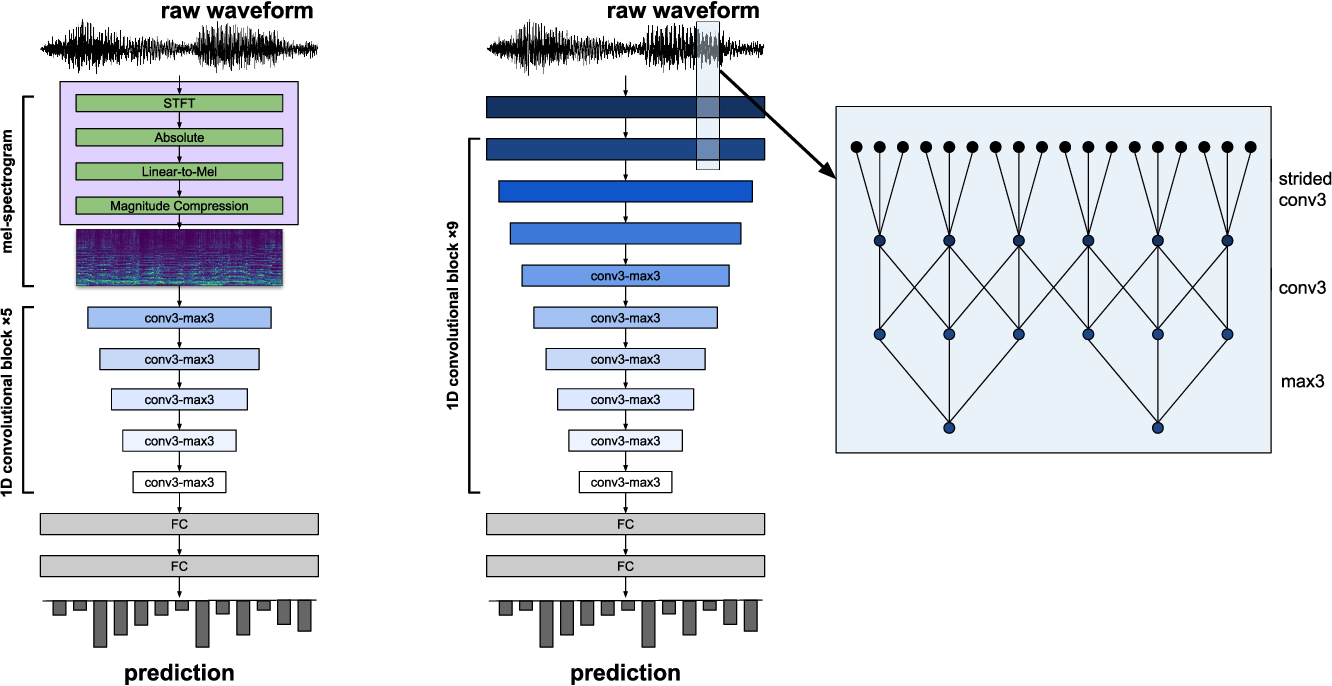
Audio Classification
We use deep convolutional neural networks for audio classification. Using state-of-the-art neural architectures, we can fine-tune the models to accurately classify live audio files for 911 operators. The following architecture is pretrained and fine-tuned on a 911 call dataset. The model has millions of parameters, making it challenging to deploy on a free server, but a pruned version is available on our backend python server.
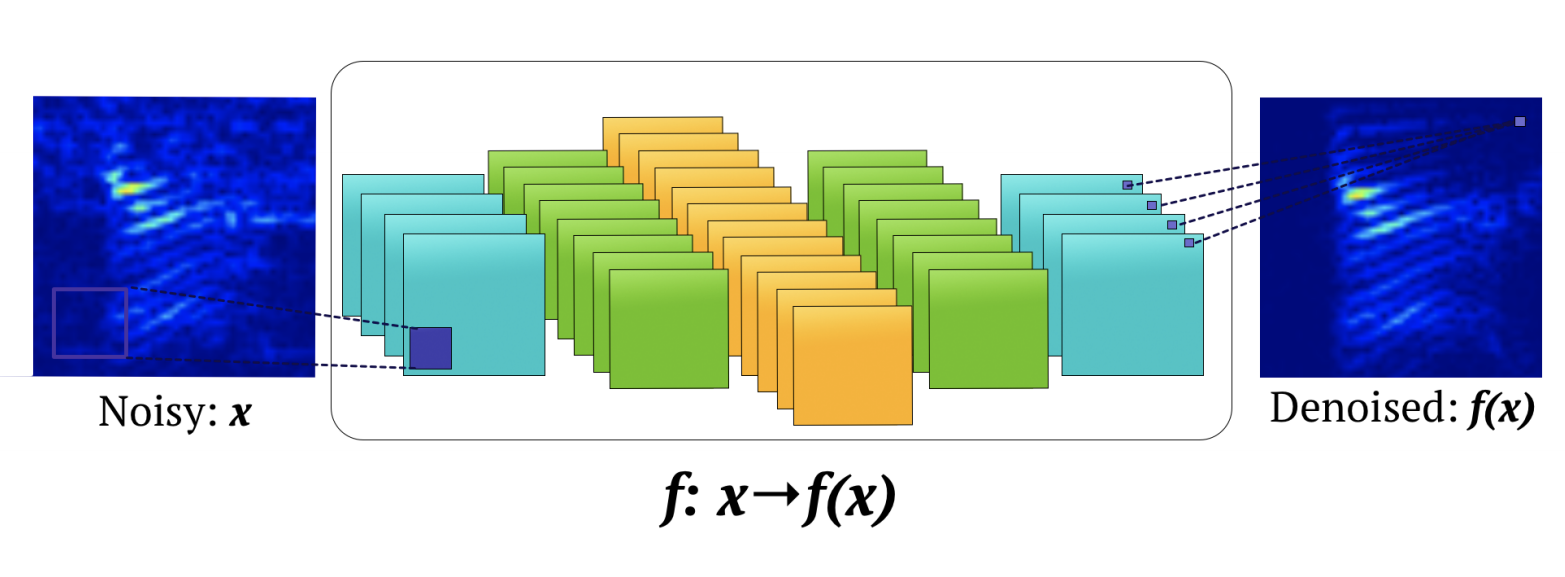
Audio Enhancement and Reconstruction
We use deep convolutional autoencoders for audio enhancement and amplification. This state-of-the-art architecture is modified to input information from the classification models regarding what dangerous noises are so they can be amplified. Moreover, the architecture is pretrained for audio enhancement, a significant challenge for 911 operators. Lastly, we build upon the multi-tasking framework and add a generative branch for predictive fill in when audio frequency becomes 0. This deep architecture is impossible to deploy given our server limitation.